
Resume
Career
Millennium Capital Partners
I currently work as a Data Scientist at Millennium at New York. I work on unsupervised (e.g. clustering), descriptive statistics, classical ML, time series analysis, anomaly detection and Deep Learning (Natural Language Processing & Speech Processing) projects that are implemented end-to-end and presented to stakeholders within the firm. Implementation of the projects include tools/frameworks like -but not limited to- Python, Jupyter notebooks, bash, PyTorch/Tensorflow, ElasticSearch, AWS.
Blisce Venture Capital
I worked as a Data Scientist/MLE at Blisce VC at New York. I worked on supervised classification ML problems, robotic process automation (RPA) tasks, deep learning (NLP) projects. I also built out the data infrastructure on AWS.
HSBC
I worked as a Quantitative Researcher at HSBC Delta One Trading Desk at Istanbul, Turkey. I worked on data engineering projects, time series analysis and meta-problems like estimation of overfitting of quantitative trading strategies.
Publications
HIGAN: Cosmic Neutral Hydrogen with Generative Adversarial Networks (GANs)
Presented at NeurIPS 2019 - Machine Learning and the Physical Science Workshop & MIT Ganocracy Workshop
Co-lead author of paper when working as a Research Scientist at Flatiron Institute - Center for Computational Astrophysics. Used GANs to generate astrophysical simulations much faster than the original simulation (IllustrisTNG) which took ~150 million CPU hours. I did literature review of GANs and Variational Encoders in addition to researching anecdotal evidence of methods to make GAN training more robust to gradient blowups etc. Implemented highly efficient data pipelines for mini-batch training to improve training speed. Conducted hyperparameter search of different GAN loss functions, architectures (DCGAN, WGAN, WGAN-GP, MMD-GAN, MMD-GAN GP, MMD GAN Repulsive Loss) and traditional hyperparameters such as learning schedules, learning rates, weight and gradient penalties. We used NYU’s HPC GPU clusters to train models with Python, Pytorch and Bash.
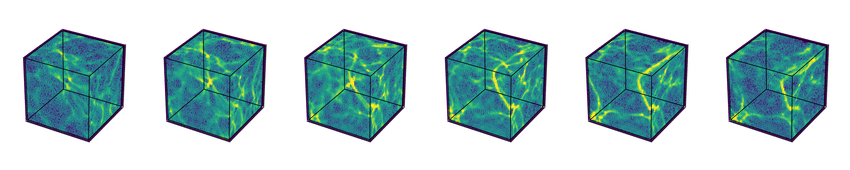 Examples of Generated Simulations
Examples of Generated Simulations
Education
New York University - MS in Data Science
Relevant Courses:
- Introduction to Data Science
- Probability and Statistics for Data Science
- Computational Linear Algebra and Optimization
- Machine Learning
- Big Data
- Deep Learning
- Natural Language Processing
- Mathematics of Deep Learning
- Advanced Python Programming
Istanbul Technical University - BSc in Industrial Engineering
Relevant Courses:
- Finance
- Econometrics
- Operations Research
- Optimization Models and Applications
- Financial Instruments and Portfolio Management
- Quantitative Research & Data Analysis
- Statistics I - II
- Accounting
- Cost Accounting
- Strategic Management for Engineers
Projects
Natural Language Processing
- Efficient Neural Architecture Search (ENAS) for text summarization task using CNN-Daily Mail data using PyTorch on GPU HPC.
- Machine Translation for Vietnamese/Chinese to English with sequence-to-sequence networks with attention using PyTorch.
Classical ML (Classification & Regression)
- Insurance renewal prediction of a severely class-imbalanced data for McKinsey datathon. Used synthetic sample creation techniques (SMOTE).
Time Series Analysis
- Prediction of agricultural goods’ inflation for Central Bank of Turkey via scraped data to improve existing prediction models.
Skills
Programming Languages: Python, R, Java, C++
Data Analysis/Modeling Frameworks: pandas, numpy, scikit-learn, scipy
Data Viz: Matplotlib, D3.js, Tableau
Deep Learning Frameworks: PyTorch, Tensorflow, Keras
Machine Learning Models: Regression, Support Vector Machines , Logistic Regression, Naive Bayes, K-Nearest Neighbors, Decision Trees, XGBoost, Random Forest, Cluster Analyses (eg.K-Means)
Deep Learning Tasks: Natural Language Processing, Computer Vision, Speech Recognition, Self-Supervised Learning, Generative Modeling (GAN & VAE)
Databases/Storage: SQL (MySQL), PostgreSQL, NoSQL (MongoDB)
Productivity Tools: Jupyter / iPython, BASH
Version Control: git, Github
Big Data Tools: Spark, Hadoop, Hive, MapReduce, ElasticSearch
Deployment/Pipeline: Docker, Kubernetes, Jenkins, Airflow
Cloud: AWS, Google Cloud
Interests
- Machine Learning & Deep Learning
- Natural Language Processing
- Language Modeling
- Relation Extraction and Knowledge Bases
- Efficient Annotation techniques
- AutoML
- Data Augmentation
- Neural Architecture Search
- Computer Vision
- Autonomous Cars
- Time Series Prediction
- Reinforcement Learning
- Natural Language Processing
- Finance
- Quantitative trading (mid-frequency)
- Central Banking and fiscal policy
- Macroeconomics
- Market microstructure
- Venture capital
- Philosophy
- History
- Psychology
- Homebrewing
- Sim Racing