
Exploring Controllable Text Generation Techniques - 2020
Information
Link: Arxiv
Paper from: Carnegie Mellon University (CMU)
Why is this paper important?: Puts different mechanisms to control generated text into a framework.
Code: NA
Summary
Controllable text generation is the task of generating text whose attributes can be controlled. These attributes are, but not limited to, stylistic, demographic and content. Stylistic attributes can be politeness, sentiment, formality; demographic attributes can be gender and age; content attributes can be information, keywords, entities, ordering of information, events. Controllable text generation can be modeled as conditional language generation task however the means of changing the attributes can be in five ways:
- External Input
- Sequential Input
- Generator Operations
- Output
- Training Objective
All of these fit into the generation process as follows:
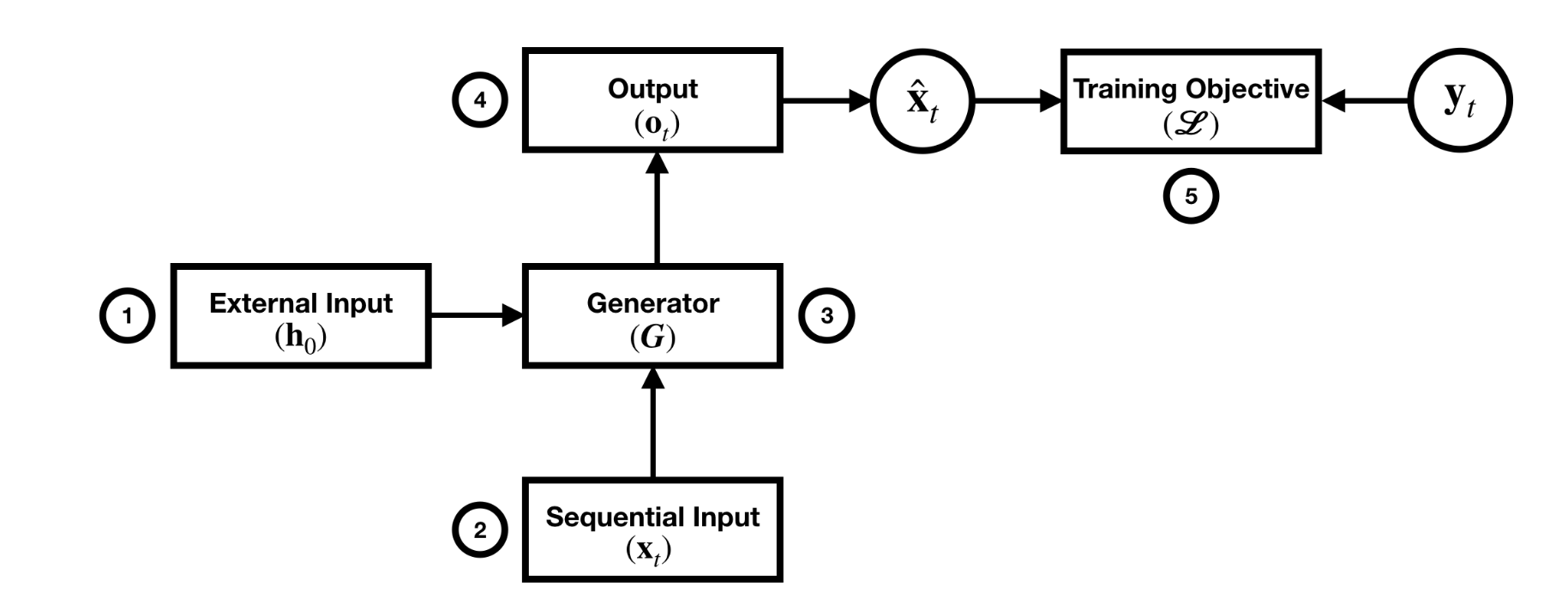
External Input
Standard (non-controlled) mechanism: \(h_{0} = h_{e}\) where \(h_0\) is the generator initialization and \(h_e\) is the representation of the input sentence by the encoder.
Controlled Mechanisms:
Arithmetic or Linear Transform
- Concatenate control vector \(s\) to \(h_{e}\): \([h_{e};s]\). Some examples:
- To control the style in text generation
- To control dialogue response generation with information from external sources
- To control visual stories with a personality control vector derived from separate corpus.
- Arithmetic operations on \(h_{e}\): Paper on visual stories also experimented with arithmetic operations instead of concatenation. \(h_{0} = h_{e} - S + P\) where \(S\) is the average representation of the story and \(P\) is the personality representation.
- Linear Transform: \(h_{0} = tanh(W_{1}h_{e} + W_{2}s + b)\). This has been reported to be performing better than the first two options.
Stochastic Changes
Stochastically draw a latent variable \(z\) from a Gaussian distribution and base \(h_{0}\) on this \(z\). This has been used to guide the generation with topics of a document. Also used to control for sentiment in style transfer task.
Decompose
This mechanism decomposes \(h_{e}\) into multiple subspaces where each subspace signifies a different attribute you wish to control. Some examples:
- Structure & semantic information of a document.
- Force the first \(n\) dimensions to capture meaning and the remaining to capture structure.
- Decompose into a form vector \(f\) and a meaning vector \(m\). A discriminator ensures \(m\) to not have any form information while another loss is used to encourage \(f\) to carry form information. \(m = tanh(W_{m}h_{e} + b_{m})\) and \(f = tanh(W_{f}h_{e} + b_{f})\).
External Feedback
An adversarial loss to alter the latent space. Some examples:
- A multi-layer perceptron is used for predicting style labels
- Multiple losses to control style and content.
Sequential Input
Standard (non-controlled) mechanism: \(x_{t}\) which is the input to the decoder at time \(t\) is not altered: \(x_{t} = y_{t-1}\) where \(y_{t-1}\) is the generated token at the previous time step.
Controlled Mechanism:
Arithmetic or Linear Transform
Concatenate a control vector \(s\) to the input of the generator at each time step: \(\tilde{x_{t}} = [x_{t};s]\). Some examples:
- Representation of external information sources concatenated as \(s\) to input of the generator.
- Concatenate side constraints that represent style and personality
- Concatenate personality representation \(P\) at each time step: \(\tilde{x_{t}} = x_{t} - S + P\) where again \(S\) is the average representation of the story.
Generator Operations
These are variant architectures used as the generator.
- Recurrent Neural Networks (RNNs)
- Transformer
- Pre-trained Models
Output
\(o_{t}\) is the output of the generator at time step \(t\) that is projected to the vocabulary space to predict the token.
Attention
- Global attention: computationally expensive for long sequences
- Local attention: much more efficient because calculated over a window size \(D\)
- Self attention: used to control for style via adding a style token to the source sequence.
External Feedback
Output latent space can be changed using adversarial loss.
- One paper encourages realistic generation and attribute compatible sentences by trying to match the distribution of sentence and vector pairs \((x,s)\)
- Another paper provides different rewards for style, semantics and fluency within a reinforcement learning setup.
Arithmetic or Linear Transform
Some examples:
- \(\tilde{o_{t}} = o_{t} + s\) where \(o_{t}\) is the output of an RNN.
- \(\tilde{o_{t}} = tanh(W_{o}o_{t} + W_{s}s + b_{o}\) .
- \(\tilde{o_{t}} = [o_{t};s]\) .
Training Objective
General Loss Objective
These objectives do not control for any attribute.
Cross Entropy Loss
The classic categorical cross entropy loss.
Unlikelihood Loss
Keeps a set of negative candidates based on repeating tokens or n-grams which are updated at each time step. This loss minimizes the repetitions and used to augment the maximum likelihood objective.
Diversity-Promoting Objective
Aims to generate varied sentences given similar inputs. Maximum Mutual Information also tries to reduce generic responses. The formula is \(\hat{\textbf{T}} = argmax_{T}{log_{p}(\textbf{T}|\textbf{S}) - \lambda logp(\textbf{T})}\)
KL Divergence
Quantifies how much one probability distribution differs from another. For prob. distributions \(P\) and \(Q\): \(KL(P||Q)\). In text domain KL Divergence is combined with evidence lower bound (ELBO).
Classifier Loss
Used to ensure that the generated tokens are inline with control attributes. This operates on the token level and is not as effective when the number of styles increase.
Task Specific Loss
Strategy Loss
Uses ground truth strategies to lead to better responses in dialogue.
Coverage Loss
Penalizes repeatedly attending to the same locations of the source document.
Structure Loss
Structural compression loss is used to generate a sentence by compressing several sentences from a specific source for the abstractive summarization task. Structural coverage is used to cover more salient information of the original document.
Comments