
Big Bird: Transformers for Longer Sequences - 2020
Information
Link: Arxiv
Paper by: Google Research
Why is this paper important?: Addresses the quadratic memory dependency of the traditional attention mechanism and proposes sparse attention that can handle longer sequences.
Code: NA
Summary
This paper addresses the limitations of the full attention used by Transformer models by intorducing sparse attention mechanism that uses memory that scales linearly to the sequence length.
Input
Start with \(\textbf{x}\) which is the input sequence that is tokenized (by classical space-separation, Byte-Pair Encoding or Wordpiece etc.):
\[\textbf{x} = (x_{1}, . . . , x_{n})\]where \(x_{1}\) would correspond to the first token. \(n\) is the sequence lenght.
Sparse Attention
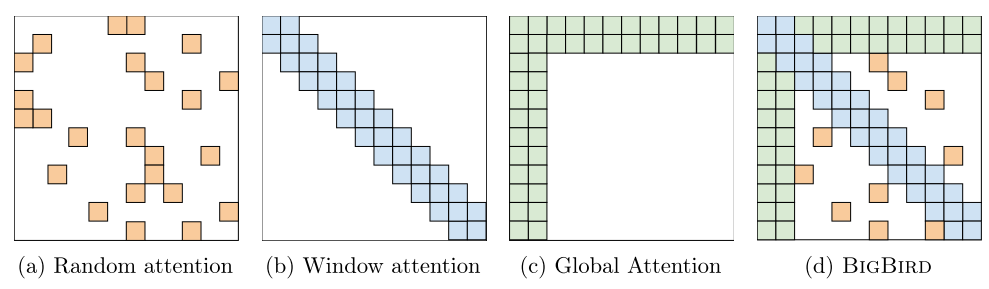
Matrix \(A\) (attention matrix) is a binary-valued \(n\)x\(n\) matrix where \(A(i,j)=1\) if query \(i\) attends to key \(j\) and is zero otherwise. When A is all 1s then it is the traditional full attention mechanism. Since every token attends to every other token, the memory requirement is quadratic.
The sparse attention consists of the merge of all three following parts (which are shown in Figure 1):
Random Attention
Each query attends over \(r\) random number of keys. Mathematically, \(A(i,\cdot) = 1\) for \(r\) randomly chosen keys.
(Sliding) Window Attention
There is a great deal of locality of reference in NLP data which is that information about a token can be derived from its neighboring tokens. To utilize this, BigBird uses a sliding window attention of width \(w\). The query at location \(i\) attends from \(i - w/2\) to \(i + w/2\) keys. Mathematically, \(A(i, i-w/2:i+w/2) = 1\).
Global Attention
Global tokens are tokens that attend to all tokens in the sequence and to whom all tokens attend to. BigBird utilizes this global token notion in two ways:
- BIGBIRD-ITC (Internal Transformer Construction): Make some existing tokens “global” and make them attend over the entire input sequence.
- BIGBIRD-ETC (Extended Transformer Construction): Add \(g\) additional “global” tokens (e.g. CLS) that attend to all existing tokens. This extends the columns and rows of the matrix \(A\) by \(g\) rows/columns.
Results
The sparse attention enables the mechanism to attend to 8x longer sequences. It is possible to use gradient checkpointing to handle >8x longer sequences. Below are results from NLP tasks. Genomics related results are omitted.
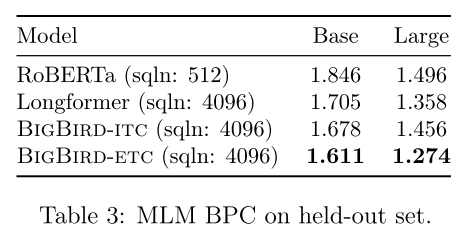
Pretraining & MLM
Encoder Only Tasks
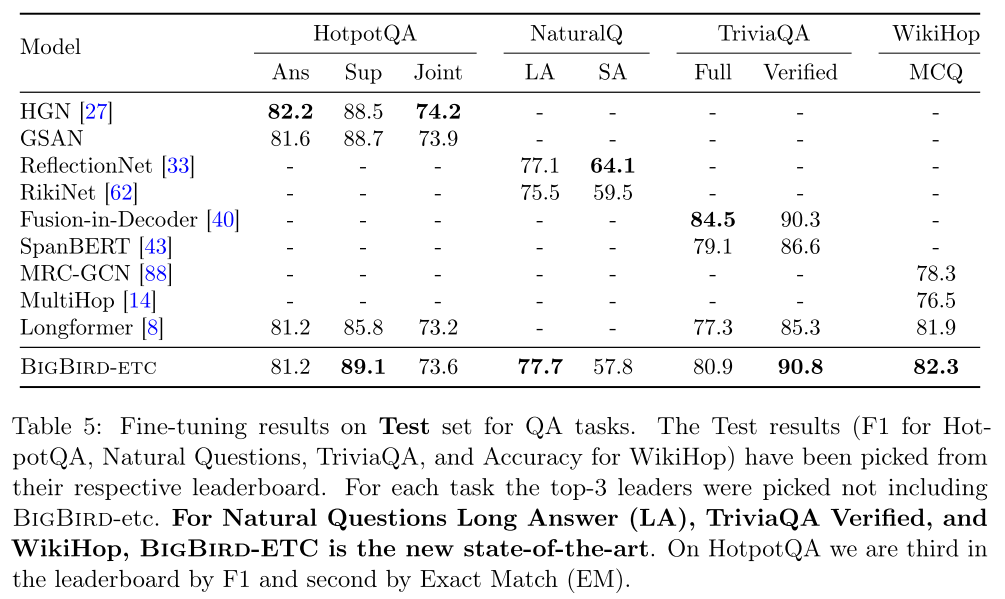
Question Answering
BigBird-ETC outperforms all other models.
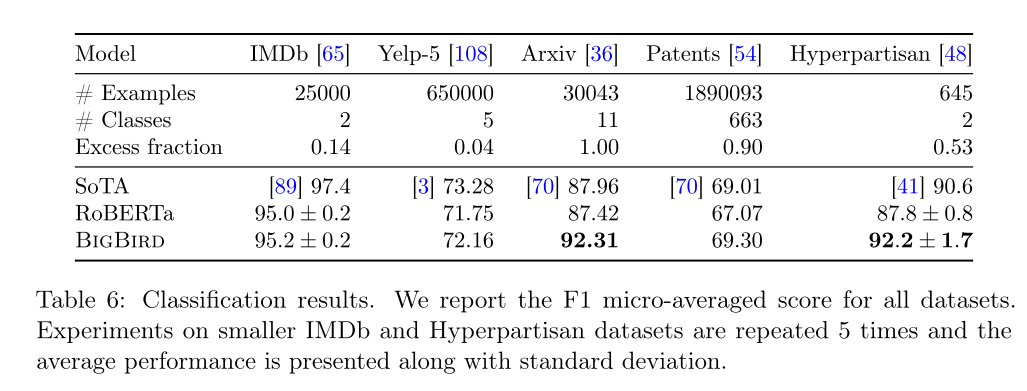
Document Classification
Improves SotA by %5 points.
Encoder-Decoder Tasks
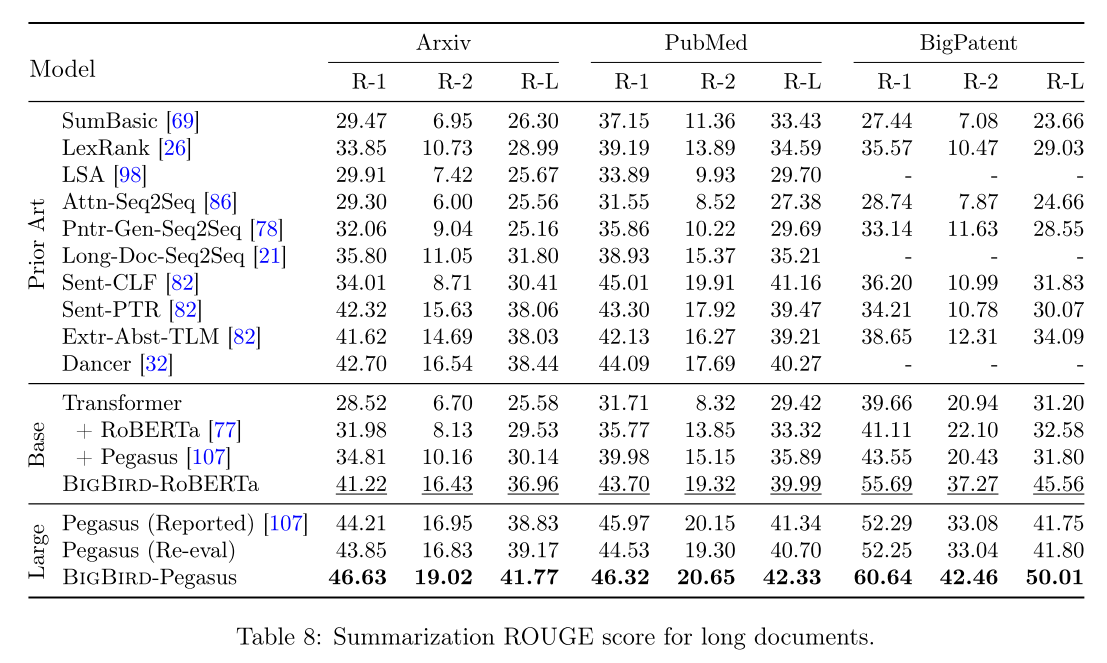
When the Pegasus pretraining is also utilized:
Comments